Build an effective system for managing conversation history while ensuring privacy and efficiency using OpenAI Models. OpenAI’s API is a powerful tool for building conversational AI applications. However, its stateless nature means that it doesn’t retain conversation history between requests. To create a seamless user experience, developers must manage and provide the conversation context manually. In this blog, we’ll explore how to handle conversation history efficiently, reduce token usage, and maintain privacy while interacting with OpenAI’s models.
Why OpenAI Doesn’t Store Conversation History
OpenAI’s API is designed to be stateless for these reasons:
Privacy and Security: By default, OpenAI does not store or retain user data unless explicitly permitted. This ensures compliance with data privacy standards.
Scalability: Stateless APIs are inherently more scalable as they treat every request independently.
This design, while advantageous, places the onus on developers to manage conversation context for dynamic and personalized interactions.
Challenges of Managing Conversation History
Token Limits: OpenAI models have token limits (e.g., ~4096 for GPT-3.5 and ~8192+ for GPT-4). Sending large amounts of history can quickly exceed these limits.
Cost Efficiency: More tokens mean higher API costs. Efficient management can save significant expenses.
Performance: Large payloads can slow down response times.
To address these, developers can implement strategies like summarization, memory management, and external storage.
Best Practices for Managing Conversation History
1. Summarizing Older Conversations
Older messages can be summarized into a concise format to preserve essential context without consuming many tokens.
Example Workflow:
Periodically summarize older exchanges using the OpenAI API.
Append the summary to the context instead of the full history.
import openai
def summarize_history(messages):
summary_prompt = "Summarize the following conversation: " + str(messages)
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a summarization assistant."},
{"role": "user", "content": summary_prompt}
]
)
return response["choices"][0]["message"]["content"]
2. Using a Rolling Window of Recent Messages
Instead of sending the entire conversation history, include only the most recent exchanges and a system message for guidance.
Example Data Structure:
conversation = {
"system_message": {
"role": "system",
"content": "You are a helpful assistant."
},
"recent_exchanges": [],
"summarized_history": ""
}
Token Management:
Add new messages to
recent_exchanges.If token usage exceeds a threshold (e.g., 3000 tokens), summarize older messages and clear
recent_exchanges.
3. External Memory with Vector Databases
Store conversation embeddings in a vector database (e.g., Pinecone, Chroma, or Weaviate). Retrieve contextually relevant past exchanges dynamically.
Advantages:
Scalable and efficient for long-term memory.
Reduces the need to include all historical messages in every request.
4. Privacy-Centric Design
To ensure user trust:
Encrypt conversation data at rest and in transit.
Mask sensitive information before storing or transmitting data.
Automatically delete user data after a specified retention period.
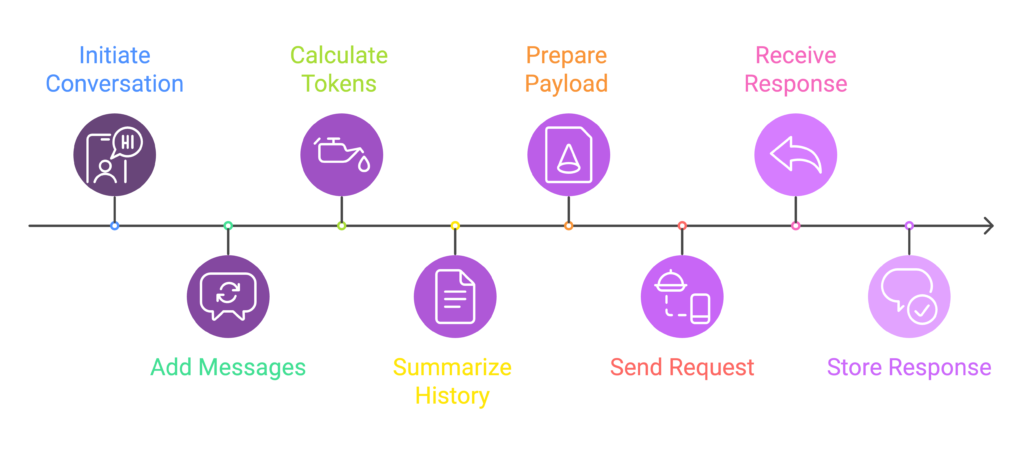
Step-by-Step Implementation
Here’s a simplified implementation:
Initialize Conversation: Define a structure to store the system message, recent exchanges, and summarized history.
Add Messages to Recent Exchanges: Use a tokenizer (e.g.,
GPT2TokenizerFast) to monitor token usage. Summarize older exchanges when necessary.Prepare the Payload: Combine the system message, summarized history, and recent exchanges before sending a request to the API.
Send the Request: Send the optimized payload to OpenAI’s API and append the response to the conversation history.
import openai
from transformers import GPT2TokenizerFast
# Initialize tokenizer
tokenizer = GPT2TokenizerFast.from_pretrained("gpt2")
def add_message(conversation, role, content):
new_message = {"role": role, "content": content}
conversation["recent_exchanges"].append(new_message)
# Calculate token usage
tokens = sum([len(tokenizer.encode(msg["content"])) for msg in conversation["recent_exchanges"]])
# Summarize if token limit is exceeded
if tokens > 3000:
summarized = summarize_history(conversation["recent_exchanges"])
conversation["summarized_history"] += summarized
conversation["recent_exchanges"] = []
def prepare_payload(conversation):
messages = [conversation["system_message"]]
if conversation["summarized_history"]:
messages.append({"role": "assistant", "content": conversation["summarized_history"]})
messages.extend(conversation["recent_exchanges"])
return messages
# Example API call
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=prepare_payload(conversation)
)
Advanced Enhancements
Real-time Summarization: Automate summarization after every few exchanges to keep the context concise.
Hybrid Memory Systems: Combine local storage for recent exchanges and vector databases for long-term memory.
Streamlined Prompts: Optimize system messages and instructions to minimize token usage.
Efficiently managing conversation history with OpenAI API is crucial for creating responsive and cost-effective applications. By leveraging techniques like summarization, rolling windows, and vector databases, developers can maintain rich conversational experiences while minimizing overhead.