Enterprises today are drowning in unstructured data. PDFs, emails, invoices, logs, contracts, and countless other document formats contain valuable business insights, but extracting that data at scale is challenging. AI agents for data engineering are emerging as a transformative solution to this problem, enabling autonomous data transformation at unprecedented speed and accuracy.
In this comprehensive guide, we’ll explore how AI agents revolutionize data engineering by automating transformation of unstructured data into structured, queryable formats. We’ll dive deep into architecture, implementation strategies, tools, and real-world applications that showcase why AI agents are becoming essential for modern data pipelines.
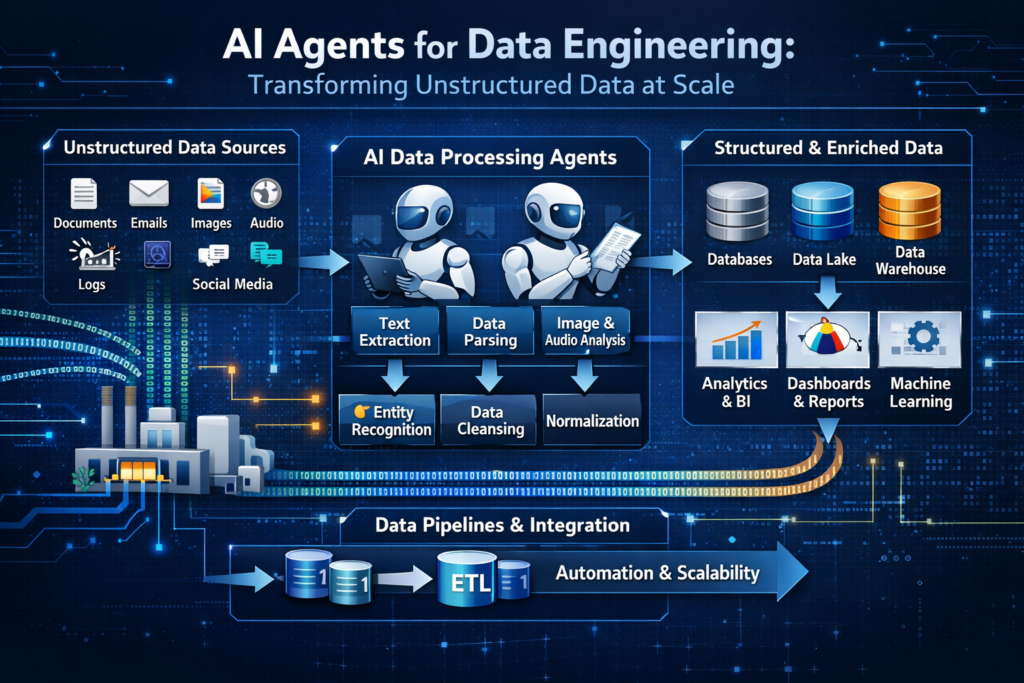
Table of Contents
- What are AI Agents for Data Engineering?
- Why AI Agents Are Revolutionizing Data Engineering
- How AI Agents Work: Architecture and Implementation
- AI Agents in Modern Data Pipelines
- Use Cases and Applications Across Industries
- Tools and Platforms
- Implementing AI Agents: Best Practices
- Challenges and Considerations
- Applying AI Agents with Virtust
What are AI Agents for Data Engineering?
AI agents for data engineering are autonomous AI systems designed to ingest, process, and transform unstructured data into structured formats without manual intervention. Unlike traditional ETL (Extract, Transform, Load) pipelines that require hard-coded rules and extensive maintenance, AI agents leverage large language models (LLMs) to understand context, make intelligent decisions, and adapt to new data patterns automatically.
These agents can read documents, extract entities, understand relationships, and map data to schemas—all autonomously. They represent a paradigm shift from rule-based data processing to intelligent, context-aware transformation that scales with your business needs.
Key Features of AI Data Engineering Agents
- Autonomous Processing: Operate without continuous human oversight, handling data transformation end-to-end
- Context Understanding: LLM-powered agents understand document context, not just patterns
- Multi-Modal Capabilities: Process PDFs, images, emails, and diverse formats seamlessly
- Scalable Architecture: Multi-agent systems can process millions of documents in parallel
- Self-Improving: Learn from feedback and adapt to new data patterns over time
Why AI Agents Are Revolutionizing Data Engineering
Traditional data engineering approaches are struggling with explosion of unstructured data. Manual extraction tools, regex patterns, and even machine learning models require significant maintenance and break when data formats change. AI agents for data engineering solve these fundamental challenges through intelligent, adaptive processing.
The Unstructured Data Challenge
According to IDC, 80-90% of enterprise data is unstructured, growing at 55-65% annually. This data includes:
- PDFs: Contracts, reports, invoices, research papers
- Emails: Customer communications, internal discussions
- Logs: Application logs, server logs, audit trails
- Documents: Meeting notes, policy documents, technical manuals
- Social Media: Customer feedback, brand mentions, trend data
Extracting value from this data manually is impossible at scale. Traditional tools fail because:
- Hard-coded Rules Break: Regex and rule-based systems fail when formats change
- Template Mismatch: Invoice extraction fails when templates vary
- Context Ignored: Pattern matching misses semantic meaning
- High Maintenance: Data engineers constantly updating extraction rules
- Slow Processing: Manual review and correction bottleneck pipelines
How AI Agents Solve These Problems
AI agents for data engineering transform this landscape by:
- Understanding Context: LLMs comprehend document meaning, not just patterns
- Adapting Automatically: Handle format changes without code updates
- Processing in Parallel: Multi-agent systems process millions of documents simultaneously
- Continuous Learning: Improve accuracy through feedback loops
- Reducing Costs: Eliminate manual data entry and review
How AI Agents Work: Architecture and Implementation
Understanding the architecture of AI agents for data engineering is crucial for successful implementation. A typical multi-agent system consists of specialized agents, an orchestrator, and robust processing pipelines working in concert.
Multi-Agent System Architecture
At Virtust, we implement AI agent architectures with four core layers:
Input Layer:
- Ingests diverse data sources: PDFs, emails, logs, databases
- Supports streaming and batch processing
- Handles authentication and access control
AI Agent Layer:
- Orchestrator Agent: Plans tasks, assigns work to specialized agents
- PDF Parser Agent: Specialized in extracting data from PDFs, handling layouts, tables, and multi-page documents
- Email Extractor Agent: Parses emails, extracts attachments, identifies senders/recipients, categorizes content
- Log Analyzer Agent: Processes server logs, identifies patterns, extracts metrics and anomalies
Processing Layer:
- Data Transformation Agent: Cleans, normalizes, and formats extracted data
- Schema Mapper Agent: Maps extracted entities to target database schemas
- Validation Agent: Ensures data quality, identifies errors, flags anomalies
Output Layer:
- Exports to structured formats: JSON, SQL, CSV, Parquet
- Integrates with databases: PostgreSQL, MongoDB, Snowflake
- Provides queryable interfaces: APIs, data warehouses, BI tools
Agent Orchestration Workflow
- Task Planning: Orchestrator receives unstructured data and plans transformation tasks
- Agent Selection: Identifies which specialized agents are needed based on data type
- Parallel Execution: Specialized agents process data simultaneously
- Result Aggregation: Orchestrator combines results from all agents
- Quality Check: Validation agent reviews aggregated results
- Output Generation: Final structured data is exported to target systems
AI Agents in Modern Data Pipelines
AI agents for data engineering integrate seamlessly into modern data architectures, enhancing existing pipelines rather than replacing them entirely. This integration enables enterprises to leverage their current investments while gaining AI-powered capabilities.
Integration Patterns
Batch Processing Integration:
- AI agents process incoming batches of unstructured data
- Structured output feeds into traditional ETL pipelines
- Ideal for daily, weekly, or monthly data updates
Streaming Integration:
- Real-time processing of incoming data streams
- AI agents transform data as it arrives
- Perfect for customer support tickets, social media, live logs
Lakehouse Integration:
- AI agents ingest from data lakes (S3, Azure Blob, GCS)
- Structured output feeds into data warehouses (Snowflake, BigQuery)
- Enables SQL querying of previously unstructured data
Performance Considerations
Production-grade AI agents for data engineering require careful optimization:
- Latency: Multi-agent parallel processing reduces overall transformation time
- Throughput: Horizontal scaling enables processing of millions of documents
- Accuracy: Ensemble approaches and validation agents ensure data quality
- Cost: Efficient prompt engineering and caching minimize LLM costs
Use Cases and Applications Across Industries
AI agents for data engineering are transforming data practices across every industry. Let’s explore real-world applications and results.
Healthcare
Healthcare organizations process millions of patient records, lab reports, and medical research papers. AI agents enable:
- Patient Data Extraction: Extract structured data from medical forms, diagnoses, and treatment plans
- Research Paper Analysis: Extract findings, methodologies, and outcomes from clinical studies
- Insurance Claims Processing: Parse claim documents, extract policy numbers, diagnoses, and amounts
- Compliance Reporting: Automatically generate regulatory reports from unstructured documentation
Finance
Financial institutions handle massive volumes of contracts, invoices, and financial statements. AI agents deliver:
- Invoice Processing: Extract line items, amounts, vendors, and payment terms from invoices
- Contract Analysis: Identify clauses, dates, obligations, and risk factors in contracts
- Financial Statement Parsing: Extract key financial metrics from annual reports
- Fraud Detection: Identify anomalies in transaction logs and communications
E-commerce
Online retailers process customer emails, product reviews, and supplier documents. AI agents provide:
- Customer Support Analysis: Extract issue types, sentiment, and resolution status from support tickets
- Product Review Extraction: Extract features, ratings, and feedback from reviews
- Supplier Contract Processing: Extract terms, pricing, and delivery schedules from supplier agreements
- Inventory Document Processing: Parse purchase orders, receipts, and shipping documents
Legal
Law firms and legal departments review contracts, case files, and regulations. AI agents enable:
- Contract Review: Extract clauses, obligations, and deadlines from legal documents
- Case File Analysis: Extract relevant facts, parties, and timelines from case materials
- Regulatory Compliance: Monitor and extract requirements from regulatory documents
- Document Categorization: Automatically sort and route legal documents
Manufacturing
Manufacturing companies maintain equipment logs, quality reports, and maintenance records. AI agents deliver:
- Maintenance Log Analysis: Extract failure patterns, root causes, and recommendations
- Quality Report Processing: Extract defect types, locations, and severity from inspection reports
- Supplier Document Processing: Extract specifications, pricing, and delivery terms
- Production Optimization: Identify bottlenecks and improvement opportunities from production logs
Tools and Platforms
Building production-grade AI agents for data engineering requires right technology stack. At Virtust, we use a combination of orchestration frameworks, LLMs, vector databases, and specialized tools to deliver scalable solutions.
| Tool/Framework | Type | Website | GitHub |
|---|---|---|---|
| LangChain | LLM Orchestration | https://langchain.com | https://github.com/langchain-ai/langchain |
| AutoGen | Multi-Agent Framework | https://microsoft.github.io/autogen/ | https://github.com/microsoft/autogen |
| CrewAI | AI Agent Orchestration | https://www.crewai.com | https://github.com/joaomdmoura/crewAI |
| OpenAI API | LLM Provider | https://openai.com | https://github.com/openai/openai-python |
| Anthropic Claude | LLM Provider | https://anthropic.com | https://github.com/anthropics/anthropic-sdk-python |
| PyMuPDF | PDF Processing | https://pymupdf.readthedocs.io | https://github.com/pymupdf/PyMuPDF |
| Tika | Document Extraction | https://tika.apache.org | https://github.com/apache/tika |
Our Recommended Stack
At Virtust, we’ve developed battle-tested approaches for AI agents for data engineering:
Orchestration: LangChain for flexible agent management and tool integration
LLMs: Anthropic’s latest models for complex reasoning, and OpenAI for cost-effective processing.
Document Processing: PyMuPDF for fast PDF extraction, Tika for multi-format support
Storage: PostgreSQL for structured output, Elasticsearch for searchable unstructured data
Implementing AI Agents: Best Practices
Successful implementation of AI agents for data engineering requires careful planning, robust architecture, and continuous improvement. Based on our experience at Virtust, here are proven best practices.
Start with a Pilot Project
Don’t try to transform all your unstructured data at once. Start with a focused pilot:
- Choose one data source (e.g., invoices, emails, PDFs)
- Define clear success metrics (accuracy, processing time, cost reduction)
- Build and test with a representative sample
- Measure results against benchmarks
- Scale successful patterns to additional data sources
Design for Error Handling
AI agents will make mistakes. Build robust error handling:
- Confidence Scoring: Agents output confidence levels for extractions
- Human-in-the-Loop: Low-confidence extractions route to human review
- Error Logging: Log all errors for analysis and improvement
- Reprocessing Queues: Failed items queue for retry with updated agents
Implement Feedback Loops
Continuous learning is critical for AI agents for data engineering:
- Human Feedback: Review agents capture corrections from human reviewers
- Active Learning: High-value training examples feed back into models
- Fine-tuning: Periodic fine-tuning improves domain-specific accuracy
- Performance Monitoring: Track accuracy, latency, and cost metrics continuously
Optimize for Cost
LLM costs can add up. Optimize strategically:
- Model Selection: Use smaller models for simple tasks, larger models for complex reasoning
- Caching: Cache common extractions to avoid repeated LLM calls
- Batching: Process multiple documents together when possible
- Prompt Engineering: Efficient prompts reduce token usage
Challenges and Considerations
While AI agents for data engineering offer transformative potential, implementation comes with challenges. Understanding these challenges prepares you for successful deployment.
Data Privacy and Security
Processing sensitive data through external LLMs raises concerns:
- PII Exposure: Personal information may be sent to third-party LLMs
- Regulatory Compliance: HIPAA, GDPR, and other regulations restrict data processing
- Solution: Use private LLM deployments, redact sensitive data before processing, or use compliant LLM providers
Accuracy and Reliability
AI agents can hallucinate or mis-extract data:
- Confidence Scoring: Implement confidence thresholds and human review for low-confidence extractions
- Validation Agents: Separate validation agents cross-check extractions
- Ensemble Approaches: Multiple agents vote on extractions to improve accuracy
Cost Management
LLM API costs scale with processing volume:
- Monitor Usage: Track tokens, requests, and costs continuously
- Optimize Prompts: Efficient prompts reduce token usage
- Model Selection: Choose the right model for each task
- Consider Local Models: For high-volume processing, self-hosted models may be cost-effective
Integration Complexity
Integrating AI agents into existing systems can be complex:
- Legacy Systems: Older systems may lack modern APIs for integration
- Data Format Variability: Diverse formats require robust parsing
- Solution: Build abstraction layers, use message queues for loose coupling, and implement gradual migration strategies
Applying AI Agents with Virtust
At Virtust, we’ve helped enterprises across industries implement AI agents for data engineering that transform their data operations. Our approach combines deep technical expertise with practical implementation strategies.
Our Process
Discovery: We start by understanding your data landscape—what unstructured data you have, where it’s stored, and what structured outputs you need.
Architecture Design: We design multi-agent architectures tailored to your specific use cases, selecting the right tools and models for optimal performance and cost.
Development: Our engineers build and test AI agents with your actual data, iterating rapidly to achieve your accuracy and performance requirements.
Integration: We integrate AI agents seamlessly into your existing data pipelines, ensuring compatibility with your current infrastructure.
Deployment: We deploy production-ready systems with monitoring, error handling, and feedback loops for continuous improvement.
Support: Our team provides ongoing support, optimization, and scaling as your data needs grow.
Why Choose Virtust
Deep Technical Expertise: Our engineers have extensive experience with LLMs, orchestration frameworks, and production AI systems.
Battle-Tested Approaches: We’ve deployed AI agents for diverse use cases across healthcare, finance, e-commerce, and more.
Competitive Pricing: We deliver enterprise-grade solutions with optimal ROI, maximizing value for your investment.
Rapid Prototyping: Get working prototypes in weeks, not months, accelerating your time to value.
End-to-End Delivery: From architecture design to deployment and support, we handle the entire lifecycle.
Ready to Transform Your Data with AI Agents?
Discover how Virtust can help you implement AI agents for data engineering that unlock value from your unstructured data. Contact our experts today to discuss your specific use cases and get a tailored implementation plan.
Contact Our AI Experts to start your journey.
Conclusion
AI agents for data engineering represent a fundamental shift in how enterprises process unstructured data. By combining autonomous agents, LLM intelligence, and robust orchestration, organizations can transform their data landscapes from chaotic silos to structured, queryable assets.
The benefits are clear: reduced manual effort, faster processing, higher accuracy, and the ability to scale with business growth. While challenges exist in privacy, accuracy, and cost, proven strategies and experienced partners like Virtust make implementation manageable and successful.
As unstructured data continues to grow, organizations that embrace AI agents today will gain a significant competitive advantage. They’ll make better decisions faster, reduce operational costs, and unlock insights previously trapped in document formats.
The future of data engineering is autonomous, intelligent, and AI-powered. Are you ready to transform your data?
Start Your AI Agent Journey with Virtust