Fine-tuning Large Language Models (LLMs) on your own data can significantly improve their performance on specific tasks. This guide provides a step-by-step explanation and technical implementation for fine-tune llm on your own data using Parameter Efficient Fine Tuning (PEFT) techniques.
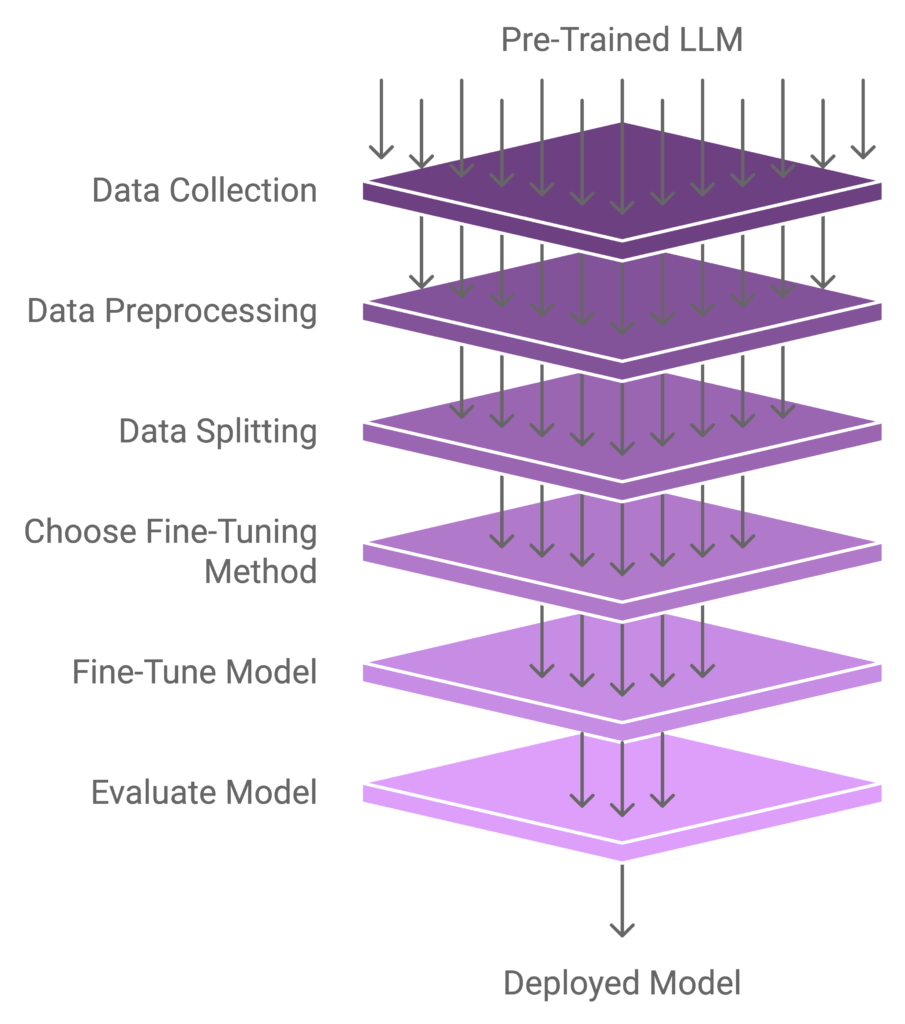
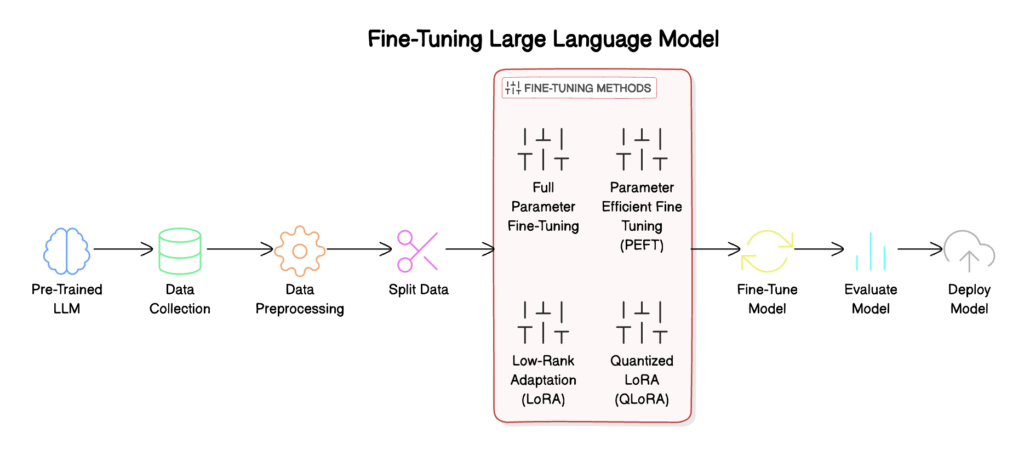
1. Introduction
Large Language Models (LLMs) have achieved remarkable success in various natural language processing tasks. However, their performance can be further improved by fine-tuning them on task-specific data. Fine-tuning large pre-trained models can be a daunting task. It requires significant computational resources, memory, and time. But what if you could fine-tune your models efficiently, without sacrificing performance?
2. Background
- A pre-trained LLM
- Task-specific data
- Computational resources
3. Preparing Your Data
- A dataset relevant to your task
- Data preprocessing (tokenization, formatting)
- Splitting data into training, validation, and testing sets
4. Choosing a Fine-Tuning Method
- Full Parameter Fine-Tuning
- Parameter Efficient Fine Tuning (PEFT)
- Low-Rank Adaptation (LoRA)
- Quantized LoRA (QLoRA)
- Low-rank matrices to capture task-specific information
- Intervention weights to control the influence of these matrices
- Reduced memory requirements
- Faster computation
- Lower precision
| LoRA | QLoRA | |
|---|---|---|
| Quantization | No | Yes (8-bit or 4-bit) |
| Memory | Moderate | Reduced |
| Computation | Moderate | Faster |
| Precision | Floating-point | Lower (8-bit or 4-bit) |
- Load your pre-trained model
- Add LoRA or QLoRA modules
- Freeze pre-trained weights
- Fine-tune LoRA or QLoRA parameters
- Evaluate your model
- Efficient fine-tuning
- Faster fine-tuning (QLoRA)
- Preserves pre-trained knowledge
- LoRA: Default PEFT choice
- QLoRA: Use when resources are limited or speed is critical
5. Technical Implementation
Full Parameter Fine-Tuning
import torch
from transformers import AutoModelForSequenceClassification
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
# Define custom dataset class
class CustomDataset(torch.utils.data.Dataset):
def __init__(self, data, tokenizer):
self.data = data
self.tokenizer = tokenizer
def __getitem__(self, idx):
text = self.data.iloc[idx, 0]
label = self.data.iloc[idx, 1]
encoding = self.tokenizer(text, return_tensors='pt', max_length=512, padding='max_length', truncation=True)
return {
'input_ids': encoding['input_ids'].flatten(),
'attention_mask': encoding['attention_mask'].flatten(),
'labels': torch.tensor(label)
}
def __len__(self):
return len(self.data)
# Initialize dataset and data loader
dataset = CustomDataset(data, tokenizer)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=32, shuffle=True)
# Fine-tune model
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=1e-5)
for epoch in range(5):
model.train()
total_loss = 0
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f'Epoch {epoch+1}, Loss: {total_loss / len(data_loader)}')
Low-Rank Adaptation (LoRA)
import torch
from transformers import AutoModelForSequenceClassification
# Load pre-trained model
model = AutoModelForSequenceClassification.from_pretrained('bert-base-uncased')
# Define LoRA modules
class LoRA(torch.nn.Module):
def __init__(self, model):
super(LoRA, self).__init__()
self.model = model
self.lora_matrices = torch.nn.ParameterList([torch.nn.Parameter(torch.randn(768, 768)) for _ in range(12)])
self.intervention_weights = torch.nn.ParameterList([torch.nn.Parameter(torch.randn(768)) for _ in range(12)])
def forward(self, input_ids, attention_mask):
outputs = self.model(input_ids, attention_mask)
for i in range(12):
outputs = torch.matmul(outputs, self.lora_matrices[i]) + self.intervention_weights[i]
return outputs
# Initialize LoRA module
lora_module = LoRA(model)
# Fine-tune LoRA parameters
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(lora_module.parameters(), lr=1e-5)
for epoch in range(5):
model.train()
total_loss = 0
for batch in data_loader:
input_ids = batch['input_ids'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
optimizer.zero_grad()
outputs = lora_module(input_ids, attention_mask)
loss
6. Conclusion
- Prepare your data carefully
- Select the most suitable fine-tuning method
- Monitor performance and adjust hyperparameters as needed
By following these guidelines and implementing the provided code snippets, you’ll be well on your way to fine-tuning LLMs and achieving state-of-the-art results in your natural language processing applications.
- For more information on LLMs and fine-tuning, refer to the Transformers library documentation and research papers.
- Experiment with different fine-tuning methods and hyperparameters to find the optimal approach for your specific task.
Next Steps:
- Apply fine-tuning techniques to your own NLP projects
- Explore other PEFT methods and techniques
- Stay updated with the latest developments in LLM fine-tuning and NLP research and learn more about how to fine-tune llm on your own data from llama fine-tuning.
Please Complete the form below and Our Tech Leads and Business Analysts contact you to discuss your project. Your information will be kept confidential.